原文:Enabling AI-Generated Content (AIGC) Services in Wireless Edge Networks
编译:DeFi 之道
简介
人工智能生成内容(AIGC)技术由于具有的独特能力 [1],在文本、图像和视频等内容领域的有着很大的应用潜力。毫无疑问,AIGC将显著影响未来的很多日常应用,特别是在元宇宙赛道。由于能够高效地生成大量高质量的内容,AIGC 可以节省在手工内容创建上的时间花费和其他资源,最近的研究表明,AIGC 在技术发展方面已经取得了重大进展。
具体来说,在文本生成方面,参考文献中[2]和[3]的作者已经探索了使用深度学习技术生成连贯和多样化文本的方法。对于图像生成,[4]和[5]作者则重点研究使用第一代对抗网络(generative adversarial networks-GANs)来生成逼真的图像。在音频生成中,[6]的作者探索了用于合成高质量语音的深度学习技术。此外,扩散模型(diffusion models)是AIGC 领域的最新突破,2020年,OpenAI 发布了 GPT-3 模型,作为一种多模式的全能语言模型,GPT-3 能够进行机器翻译、文本生成、语义分析等[7]。而在2022年发布的基于扩散模型的 DALL-E2 被认为是最先进的图像生成模型,其性能可以优于GANs [8]。
但是,AIGC 模型需要大量的数据来进行训练,而且大型的 AIGC 模型还很难被部署。以 Stable Diffusion 为例,Stability AI 公司维护了超4000个NVIDIA A100 GPU集群,运营成本就达到了5000万美元。而 Stable Diffusion V1 模型的一次训练需要15万A100 GPU小时。此外,由不同数据集训练的 AIGC 模型只能适用于特定的任务,例如,由人脸数据集训练的 AIGC 模型可以用于修复损坏的人脸图像,但不能有效地纠正模糊的景观图像。由于用户任务的多样性和有限的边缘设备容量,很难在每个网络边缘设备上部署多个 AIGC 模型。为了进一步提高 AIGC 服务的可用性,一个很有前途的部署方案是基于“Everything-as-a-service”(EaaS),它可以有效地为用户提供基于订阅的服务。通过采用EaaS部署方案,我们进一步提出了“AIGC-as-a-service”(AaaS)的概念,具体来说就是 AIGC 服务提供商(ASPs)可以在边缘服务器上部署人工智能模型,通过无线网络向用户提供即时服务,提供更方便和可定制的体验。用户可以轻松地访问和享受 AIGC 的低延迟,在边缘网络中部署 AaaS 有几个优点:
个性化:AIGC 模型可以根据每个用户的需求进行定制的内容,提供个性化的体验。例如,可以提供个性化的产品推荐,通过根据用户的位置、偏好和使用模式给用户提供服务。
高效率:通过在更接近用户的地方部署AIGC服务,服务质量(QoS)将得到显著提高,例如,通过本地的内容传输,可以更有效地利用网络和计算资源,降低延迟。
灵活性:AIGC 可以进行定制和优化,以满足动态需求和资源可用性。通过调度无线网络用户对 AIGC 的访问,可以使网络中用户的整体QoS最大化。
因此,基于边缘网络的 AaaS 有可能彻底改变通过无线网络来创建和交付内容的方式。然而,目前对 AIGC 的研究主要集中在 AIGC 模型的训练上,而忽略了在无线边缘网络中部署 AIGC 时的资源分配问题。具体来说,AIGC 可能需要大量的带宽和计算能力来生成内容以及向用户交付内容,而这可能会导致网络性能的下降。此外,扩展 AaaS 以满足大量用户的需求也是一项挑战。因此,为用户分配合适的 AIGC 服务提供商(ASPs)至关重要的,一方面,用户追求那些能提供优质服务的 ASPs;另一方面,也要避免某些 AIGC 服务过载和需要重新传输,从而消耗稀缺的网络资源,文章主要有以下几个方面的内容:
对AIGC及其背后的技术的全面概述,讨论了 AIGC 的各种应用及其在无线边缘网络中的用例和部署挑战。
回顾了现有的基于图像的感知质量指标。通过实际实验,我们提出了一个通用模型来揭示AaaS中计算资源消耗与生成内容质量之间的关系。
提出了一种支持深度强化学习(DRL)的方法来实现最优 ASPs 的动态选择。证明了DRL算法相比其他四种解决方案上的优势。
AI内容生成与技术
在本节中,我们将回顾 AIGC 的发展进展,介绍了 AIGC 背后的技术。然后,我们将讨论几种AIGC 在边缘网络中的相关应用。
1. 生成技术(Generative Techniques)
我们在训练 AIGC 模型[9]中引入了生成技术,基本模型结构下图所示。
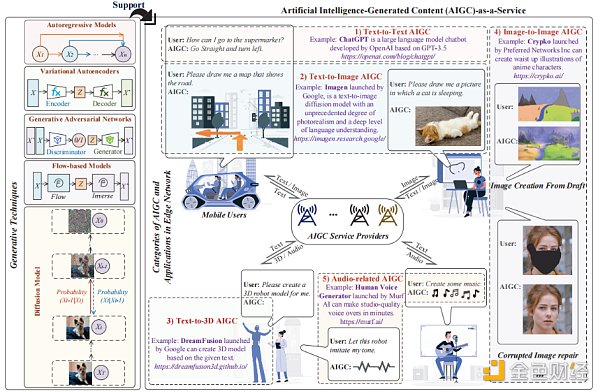
图1:AIGC [9]中的生成技术、AIGC的类别和在无线边缘网络中的应用
l 自动回归模型(ARMs): ARMs属于统计模型,它涉及到基于过去的值[9]来预测一个时间序列的未来值。ARMs可以通过基于前一个元素预测下一个元素来生成文本或其他媒体类型。ARMs的一个潜在应用是,通过根据边缘用户之前的音符来预测音乐序列中的下一个音符,进而来生成音乐。
变分自编码器(VAEs): VAEs可以通过学习输入数据来生成新的数据,其中包括一个编码器网络和一个解码器网络[9]。编码器网络处理输入数据并输出一个潜在的表示,解码器网络以这种潜在的表示作为输入,并生成与输入数据相似的合成数据。
生成对抗网络(GANs): GANs由两个神经网络组成,即生成器网络和鉴别器网络[4]。将这两个网络一起进行训练,以提高生成器生成真实图像的能力和鉴别器区分合成图像和真实图像的能力。
基于流的模型(FBMs): FBMs通过一系列可逆变换[9]将一个简单的分布转换为目标分布,这些转换被实现为神经网络,而应用这些转换的过程被称为“流(Flow)”。
扩散模型(DMs):训练DMs对被高斯噪声模糊的图像进行去噪,以学习如何实现逆转扩散过程[8]。几种基于扩散的生成模型已经被提出,包括扩散概率模型、噪声条件评价网络和去噪扩散概率模型等。
此外,经典的技术,如 Transformer,也可以用于训练 AIGC 模型,这将在下面进行讨论。
2. 移动网络中的AIGC与应用程序类别
下文介绍了几类 AIGC 技术及其在边缘网络中的应用,这可以作为未来潜在的研究方向。
文本到文本的 AIGC:文本到文本 AIGC 可以根据给定的文本输入生成类人的回复输出。因此,它可以用于自动回答、语言翻译或文章摘要。一个代表性的文本到文本 AIGC 模型就是GPT(https://openai.com/blog/chatgpt/),它是由 OpenAI [7]开发的语言模型。GPT 是在大量生成的文本数据集上训练的,比如书籍或文章,该模型可以根据前面的单词来预测序列中的下一个单词并创建文本。GPT 非常成功,并且已经在几个自然语言处理(NLP)基准测试上取得了非常好的效果。GPT 可以用来构建许多基于语言的服务,在无线边缘网络中,如图1所示,GPT可以作为一个聊天机器人,为司机提供导航和信息警报等服务。
文本到图像的 AIGC:文本到图像 AIGC 允许用户基于文本输入来生成图像,允许通过书面描述创建对应的视觉内容。它可以被看作是自然语言处理和计算机视觉技术的结合。如图1所示,文本到图像的 AIGC 可以帮助移动用户进行各种活动。例如,车联网中的用户可以请求基于视觉的路径规划,此外,文本到图像的 AIGC还 可以帮助用户创建艺术,并根据用户的描述或关键字创作各种风格的图片。
文本到 3D 的 AIGC:文本到 3D AIGC 可以通过使用无线AR应用程序从文本描述生成3D模型。通常,生成3D模型比生成2D图像需要更高的计算资源。考虑到下一代互联网服务的发展,如元宇宙[10],基于文本来生成3D模型而无需复杂的手工设计,未来将会有非常大的应用潜力。
图像到图像的 AIGC:指使用人工智能模型从源图像中生成真实的图像,或创建输入图像的程式化版本。例如,当涉及到辅助艺术品创作时,图像到图像的 AIGC 可以仅根据用户输入的草图生成视觉上令人满意的图片。此外,图像到图像的 AIGC 还可以用于图像编辑服务,比如用户可以删除一个图像中的遮挡或修复损坏的图像。
与音频相关的 AIGC:与音频相关的AIGC模型可以分析、分类和操作音频信号,包括语音和音乐。具体来说,文本到语音模型的设计是为了从文本输入中合成自然的语音。音乐生成模式可以综合各种风格和流派的音乐。视听音乐的生成包括使用音频和视觉信息,如音乐视频或专辑艺术作品,以生成与特定视觉风格或主题更紧密相关的音乐作品。此外,与音频相关的 AIGC 可以作为语音助手,回答用户的查询。Alexa 和 Siri 是现实应用程序的例子。
鉴于 AIGC 模型的强大能力,在无线边缘网络中部署 AaaS 存在几个挑战,下面将介绍这些挑战。
AaaS与无线边缘网络
在本节中,我们将详细讨论AaaS,包括挑战和性能指标。
AaaS 的挑战
为了在无线边缘网络中部署 AaaS,ASPs 首先应该在大数据集上训练 AIGC 模型。AIGC 模型和边缘网络生成技术中的应用程序扩散模型需要托管在边缘服务器上,并且可以被用户访问。需要持续的维护和更新,以确保 AIGC 模型在生成高质量内容方面保持准确和有效。用户可以提交内容生成请求,并从 ASPs 租用的边缘服务器接收生成的内容。尽管在无线边缘网络中部署 AaaS 有优点,但仍有相应的挑战需要解决:
带宽消耗:AIGC 消耗了大量的带宽。特别是对于与高分辨率图像相关的 AaaS,上传和下载过程都需要大量的网络资源来实现,来确保低延迟的服务。例如,在壁纸天堂应用中,一个人工智能生成的壁纸的数据大小可以达到10兆字节左右。此外,由于生成的图像的多样性,用户可能为了获得满意的图像,向特定的边缘服务器进行多次重复请求,进一步消耗网络资源。
时变频道质量:AaaS 中的 QoS 会受到生成内容的无线传输影响。低信噪比(SNR)、低中断概率(OP)和高误码概率(BEP)会降低 AIGC 服务的 QoS 和用户满意度,这是时变信道偶尔遇到深度衰落时造成的。
用于训练 AIGC 模型的数据集:用于训练 AIGC 模型的数据集可能会影响生成内容的质量。由于不同的 ASPs 有不同的 AIGC 模型,用户可以被分配到合适的 ASPs 来满足他们的需求。例如,使用了更多的人脸图像进行训练的 AIGC 模型将比使用其他数据集进行训练的 AIGC 模型更适合生成虚拟化身。
计算资源消耗:训练有素的 AIGC 模型在生成内容时仍然消耗一定的时间和计算资源,例如,扩散模型AaaS的输出质量随着推理步骤数的增加而增加。
l 效用最大化和激励机制:激励机制的设计在 AaaS 中具有重要意义,因为它可以激励 ASPs 生成高质量的内容,满足期望的目标和目标。
解决上述挑战的一个常见问题是如何评估 AIGC 的性能。虽然目前市面上已经提出了许多不同模式的评估指标,但大多数都是基于人工智能模型或者本身难以计算,没有数学表达式。对于无线网络中 AaaS 的优化设计,基于人工智能的资源分配解决方案可以利用基于人工智能的性能指标来模拟对用户的主观感受。然而,传统的数学资源分配方案需要有对计算资源消耗的关系,如扩散模型中的推理步数与生成内容的质量之间的关系进行建模,如图2所示。为了解决这一问题,我们以与图像相关的 AaaS 为例,引入了各种性能评价指标,并探讨了度量值之间的数学关系。
性能指标
我们首先讨论 AIGC 的评估指标。我们专注于评估图像的感知质量,但同样的方法也可以应用于其他类型的内容,我们还建立了 AaaS 中计算资源消耗与生成内容质量之间的关系。
1) 基于图像的指标:图像质量评估指标可以是基于分布的和基于图像的。基于分布的度量标准,例如,弗雷切特初始距离[11],取一个图像特征列表来计算分布之间的距离,以评估生成的图像。然而,对于无线网络中的实际 AaaS,质量评价是主观的,用户很难计算出基于分布的指标。因此,我们关注基于图像的指标,试图通过建模人类视觉系统的生理和心理视觉特征,或通过信号保真度度量来实现对质量预测的一致性。具体来说,如果不以原始图像作为参考,无参考图像质量评价方法可以被认为是[11]:
全分辨(TV):TV 是对图像平滑度的一种度量。计算全分辨的一种常见方法是取图像中相邻样本之间的绝对值之和,它衡量了图像的“粗糙度”或“不连续性”。
无参考的空间域图像质量评估(BRISQUE):BRISQUE 用局部归一化亮度系数的场景统计数据来量化由于[12]失真而可能造成的图像“自然性”损失,研究表明,BRISQUE 表现与人类对图像质量的感知类似。
图像质量越高,TV 值越小,对于有参考图像的 AaaS,我们可以使用全参考图像质量的评价方法[11]:
离散余弦变换图像质量评价(DSS):DSS 通过测量离散余弦变换(DCT)域的结构信息变化,利用人类视觉感知的基本特征,对这些次频带[13]的质量进行加权计算。
基于Haar小波的感知相似性指数(HaarPSI): HaarPSI利用从Haar小波分解得到的系数来评估两幅图像之间的局部相似性,以及图像区域的相对重要性。
平均偏差相似指标(MDSI): MDSI 利用梯度相似度、色度相似度和偏差池等,是一个可靠和完整的参考感知图像质量评估的模型。
视觉信息保真度(VIF): VIF 是一种有竞争力的测量保真度的方法,它量化了参考图像中的信息,以及从失真图像中可以提取多少参考信息。
图像质量越高,上述衡量图像质量的度量值就越高。
2) 感知图像质量度量值的一般模型:基于扩散模型的 AIGC 模型正在成为主流。如图1的所示,扩散过程可以看作是一个逐级去噪的过程。因此,增加推理步骤的数量将提高感知图像的质量。然而,生成的图像质量并不总是随着步骤数的增加而增加。过度的推理步骤会导致不必要的资源消耗。我们进行了真实的实验来调查推理步骤数和各种感知图像质量指标之间的关系,即TV、BRISQUE、DSS、HaarPSI、MDSI 和 VIF。
实验平台建立在一个通用的 Ubuntu 20.04 系统上,AMD 锐龙Threadripper PRO 3975WX 处理器规格和NVIDIA RTX A5000 的GPU。我们以基于扩散模型的损坏图像恢复服务作为 AaaS为例子。具体来说,我们在服务器上部署了[14]中提出的训练有素的模型 RePaint。如图2(A部分)所示,我们首先生成一系列损坏的图像,例如20张图像。然后,将这些损坏的图像输入“重新绘制”。我们可以观察到,随着推理的进行,损坏的图像逐渐恢复,如图2(D部分)所示。此外,衡量图像质量的BRISQUE度量值下降,如图2(B部分)所示。我们在图3中展示了在不同的时间和推理步骤下的各个度量值的变化。
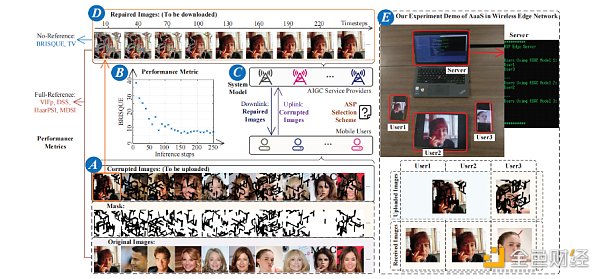
图2:用于修复损坏的图像的AaaS示例
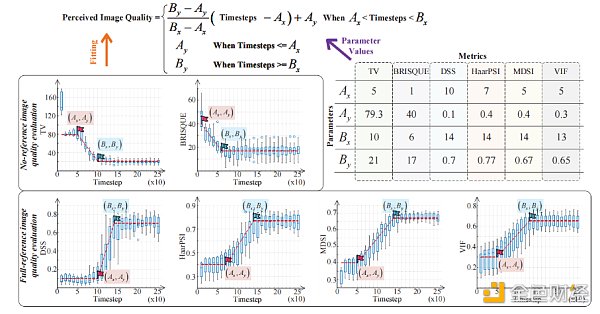
图3. 推理步骤的数量与不同感知图像质量指标之间的关系
因此,我们给出了一个包含四个参数的感知图像质量度量的一般模型,如图3的顶部所示。具体来说,Ax是图像质量开始提高时的最小推理步骤数,Ay是图像质量的下限,可以视为高噪声图像的评价值,Bx是根据 AIGC 模型的能力而使图像质量开始稳定时的推理步骤数,By是模型所能达到的最高图像质量的值。无论性能度量值与图像质量成正比还是成反比,无论AaaS类型如何,我们都可以很容易地通过实验找到点(Ax,Ay)和(Bx,By),如图3所示。
经验教训:尽管扩散过程存在固有的不确定性,但从图3中我们可以观察到,感知到的图像质量随着推理步骤的增加而近似成比例的增加或下降。在实际的 AIGC 模型分析中,我们可以用图3所示的简单拟合方法对一个性能度量进行实验,得到我们提出的一般数学模型中的四个参数。然后,该模型可用于无线边缘网络支持的 AIGC 服务分析。
深度强化学习的动态ASPs选择
在本节中,我们研究了最优的 ASPs 边缘服务器选择问题。我们提出了一个支持 DRL 的解决方案,以最大化实用功能,同时满足用户的需求。
AaaS系统模型
如我们的演示图2 (E部分)所示,三个用户分别在两个图像修复 AIGC 模型中进行选择,在 CelebA-HQ 和 Places2 [14]数据集上进行训练。用户1和用户2上传了相同的损坏图像,我们可以观察到不同的 AIGC 模型对于相同的用户任务会产生不同的结果。
进一步研究了在无线边缘网络中大规模部署 AaaS 的情况,模拟设置了20个AIGC服务提供商(ASPs)和1000个边缘用户。每个 ASPs 为 AaaS 提供最大的资源容量,即在一个时间窗口内的总扩散步数,在 600 到1500 范围内随机,每个用户在不同的时间向 ASPs 提交多个 AIGC 任务请求。这些任务指定了其所需要的 AIGC 资源的数量,即扩散步数,我们将其设置为一个在100到250之间的随机值,用户任务的到达情况遵循泊松分布。具体来说,在288小时内,用户任务到达速率λ=0.288h/请求,总共有1000个任务。需要注意的是,由不同的 ASPs提供的AIGC模型的质量是不同的,例如,修复后的图像可以更真实和自然。
一个简单但不太有效的 ASPs 选择是,用户将任务请求直接发送到生成内容质量最好的 ASPs。然而,由于计算资源不足和实践中任务可能中断,这种方法不可避免地使一些 ASPs 过载,此外,用户此时也不知道 ASPs 生成内容的质量。移动用户需要多次要求 ASPs 来估计生成内容的质量,以进行近似选择,这带来了不必要的负载和无线网络资源消耗。为此,在生成内容质量未知的前提下,如何为用户任务选择合适的 ASPs,最大限度地提高整个系统的效用,减少集中某个 ASPs 造成的 AIGC 资源过载和中断问题,是一个具有挑战性但又非常重要的问题。
基于深度强化学习的解决方案
我们使用 Soft Actor-Critic(SAC软行为者-批评者)DRL [15]来解决上述动态 ASPs 选择问题。如图4所示,学习过程在评估(批评者)和改进(行为者)之间交替进行。与传统的行为者-批评者体系结构不同,SAC 中的策略被训练为最大限度地在预期回报和信息熵之间进行权衡。AaaS环境中的状态空间、动作空间和奖励的定义如下:
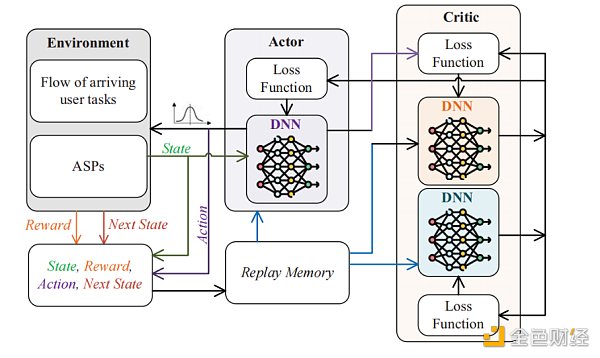
图4:The structure of soft actor–critic DRL algorithm.
状态:状态空间由两部分组成,(a) 到达的用户任务的特征向量(当前用户任务对AIGC资源的需求和任务的估计完成时间;(b) 当前状态下所有 ASPs 的特征向量(i个 ASPs 的总 AIGC 资源和第i个 ASPs 的当前可用资源)。
动态:ASPs 选择问题的动态空间是一个表示所选 ASPs 的整数。
奖励:包括两部分,生成内容的质量奖励和拥塞惩罚。前者被定义为修复后的图像的感知质量。此外,任何超载 AIGC 模型的操作都必须作进行惩罚。首先,行为本身应该受到固定的惩罚。其次,考虑到操作原因会导致 ASPs 的模型崩溃,并且正在运行的任务将被中断,当前的操作也会根据正在进行的任务的进度受到额外的惩罚。返回的总回报是质量奖励减去拥塞惩罚。
图5显示了启用了 DRL 后的 ASPs 选择策略和四个基准测试策略的效用曲线(即奖励曲线)。由于 DRL 可以学习和进化,随着学习步骤的进展,DRL 对 ASPs 的选择更全面、更准确。因此,效用迅速上升,显示出独特的学习能力。一个有趣的发现是,当DRL超过循环时,DRL已经有了一个特定的负载平衡能力,此时,DRL已经学会了避免可能导致崩溃的操作,从而避免了拥塞惩罚。然后,DRL开始学习不同的 ASPs 的优先级,并寻求将当前的用户任务放在高质量的 ASPs 上,以最大化奖励。
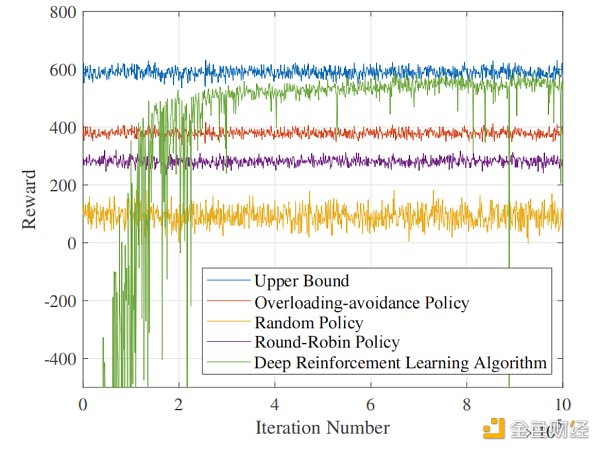
图5:奖励值与DRL中迭代次数的关系
图6计算了五种策略下 AIGC 任务崩溃的数量、已完成任务的平均奖励和崩溃任务的数量。一方面,启用了 DRL 的 ASPs 选择策略可以实现零任务崩溃,并将拥塞惩罚最小化,这对于为用户提供令人满意的生成内容质量至关重要。另一方面,DRL 策略可以了解 ASPs 可能提供的内容质量,而这在其他策略中是未知的。然后,DRL 可以将用户任务分配给能够提供更高 QoS 的 ASPs,从而有效地增加每个任务的平均奖励。以上两个优势的结合最终使得 DRL下的 ASPs 选择策略能获得更高的奖励。
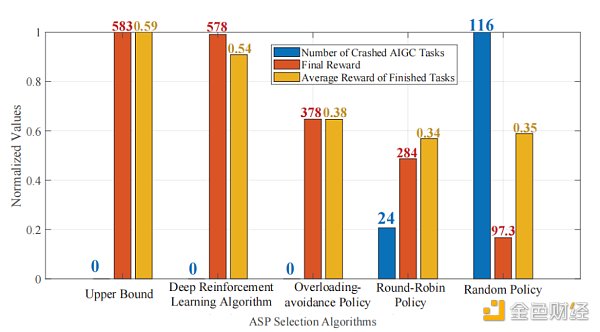
图6:五种策略下的任务崩溃的数量、已完成任务的平均奖励和崩溃任务统计
未来方向
Assa安全
在无线网络中部署 AaaS 时,来自用户的请求和生成的内容都是在无线环境中传输的。因此,需要研究 AIGC 的安全技术,例如,通过改进物理层安全技术来保护 AIGC 数据的传输,此外,区块链可以用于实现分布式的内容分发,允许在用户之间直接共享和访问内容,而不需要一个中央节点。通过区块链验证 AIGC 的真实性和来源,确保 AIGC 的准确和可信。此外,在 AIGC 模型的训练过程中,需要保证训练数据的隐私性,特别是生物特征数据,如人脸图像等数据的安全,一种可能的解决方案是通过 federated learning 模型来进行训练。
基于物联网和无线传感辅助的 AaaS
考虑到传感技术的快速发展,我们的目标是利用无线传感信号实现无源 AaaS。例如,无线传感器可以收集有关环境或用户行为的数据,然后可以将这些数据输入到 AIGC 模型中,以生成相关的内容,这可以被应用到医疗保健,比如借助使用物联网设备,通过无线传感来检测用户的活动水平、睡眠模式或心率,AIGC 可以生成个性化锻炼计划等内容。
AaaS的个性化资源分配
虽然目前的 AIGC 模型可以通过定制化来满足用户的需求,但还需要更多的研究来实现个性化的AIGC服务。例如,对于文本到图像的 AaaS,当两个用户都输入文本“一只猴子站在一只斑马旁边”时,当前的 ASPs 会为用户生成类似的图像,但是,如果我们推断这两个用户分别是驯马师和猴子研究者,我们就可以进行个性化的计算资源分配[10]。具体来说,应该分配更多的计算资源来为驯马师生成和传输图像中的斑马。对于猴子研究人员来说,更适合生成猴子图像的 AIGC 模型应该被分配来处理这个任务。一个潜在的解决方案是将用户反馈和偏好纳入到内容生成过程中,并开发评估个性化内容有效性的技术。
总结
在本文中,我们回顾了 AIGC 技术,并讨论了其在无线网络中的应用。为了向用户提供 AIGC服务,我们提出了 AaaS的 概念。然后,讨论了在无线网络中部署 AaaS 所面临的挑战。在解决这些挑战时,一个基本的问题是关于资源消耗和生成内容的感知质量之间的数学关系。在探索了各种基于图像的性能评价指标之后,我们提出了一个通用的建模方程,此外,我们还研究了重要的 ASPs 选择问题。采用DRL算法实现了接最优的 ASPs 选择,我们希望本文能够激励研究人员为无线边缘网络感知的 AaaS 发展做出贡献。
参考目录:
[1] L. Yunjiu, W. Wei, and Y. Zheng, “Artificial intelligence-generated and human expert-designed vocabulary tests: A comparative study,” SAGE Open, vol. 12, no. 1, Jan. 2022.
[2] M. Chen, A. Radford, R. Child, J. Wu, H. Jun, D. Luan, and I. Sutskever,“Generative pretraining from pixels,” in Proc. Int. Conf. Mach. Learn.PMLR, 2020, pp. 1691–1703.
[3] J. Guo, S. Lu, H. Cai, W. Zhang, Y. Yu, and J. Wang, “Long text generation via adversarial training with leaked information,” in Proc.AAAI Conf. Artif. Intell., vol. 32, no. 1, 2018.
[4] T. Karras, T. Aila, S. Laine, and J. Lehtinen, “Progressive growing of gans for improved quality, stability, and variation,” in Proc. Int. Conf.Mach. Learn., 2018.
[5] X. Huang, M.-Y. Liu, S. Belongie, and J. Kautz, “Multimodal unsupervised image-to-image translation,” in Proc. Eur. Conf. Comput. Vis.,2018, pp. 172–189.
[6] W. Ping, K. Peng, K. Zhao, and Z. Song, “WaveFlow: A compact flowbased model for raw audio,” in Proc. Int. Conf. Mach. Learn. PMLR,2020, pp. 7706–7716.
[7] L. Floridi and M. Chiriatti, “GPT-3: Its nature, scope, limits, and consequences,” Minds Mach., vol. 30, no. 4, pp. 681–694, Apr. 2020.
[8] P. Dhariwal and A. Nichol, “Diffusion models beat GANs on image synthesis,” Adv. Neural Inf. Process. Syst., vol. 34, pp. 8780–8794, 2021.
[9] G. Harshvardhan, M. K. Gourisaria, M. Pandey, and S. S. Rautaray,“A comprehensive survey and analysis of generative models in machine learning,” Comput. Sci. Rev., vol. 38, p. 100285, 2020.
[10] H. Du, J. Liu, D. Niyato, J. Kang, Z. Xiong, J. Zhang, and D. I. Kim,“Attention-aware resource allocation and QoE analysis for metaverse xURLLC services,” arXiv preprint arXiv:2208.05438, 2022.
[11] S. Kastryulin, D. Zakirov, and D. Prokopenko, “PyTorch Image Quality:Metrics and measure for image quality assessment,” 2019, opensource software available at https://github.com/photosynthesis-team/piq.[Online]. Available:https://github.com/photosynthesis-team/piq
[12] A. Mittal, A. K. Moorthy, and A. C. Bovik, “No-reference image quality assessment in the spatial domain,” IEEE Trans. Image Process., vol. 21,no. 12, pp. 4695–4708, Dec. 2012.
[13] L. Gatys, A. Ecker, and M. Bethge, “A neural algorithm of artistic style,”J. Vis., vol. 16, no. 12, pp. 326–326, Dec. 2016.
[14] A. Lugmayr, M. Danelljan, A. Romero, F. Yu, R. Timofte, and L. Van Gool, “Repaint: Inpainting using denoising diffusion probabilisticmodels,” in Proc. IEEE Conf. Comput. Vis. Pattern Recognit., 2022, pp.11 461–11 471.
[15] P. Christodoulou, “Soft actor-critic for discrete action settings,” arXiv preprint arXiv:1910.07207, 2019.